ctguoj-cli校oj命令行版
python大作页做了一个校oj的命令行版. 源于之前刷LEETCODE使用 leetcode-cli 体验到了屌丝般顺滑…
开发环境:
- python3
- centos7.4 (64
功能演示:
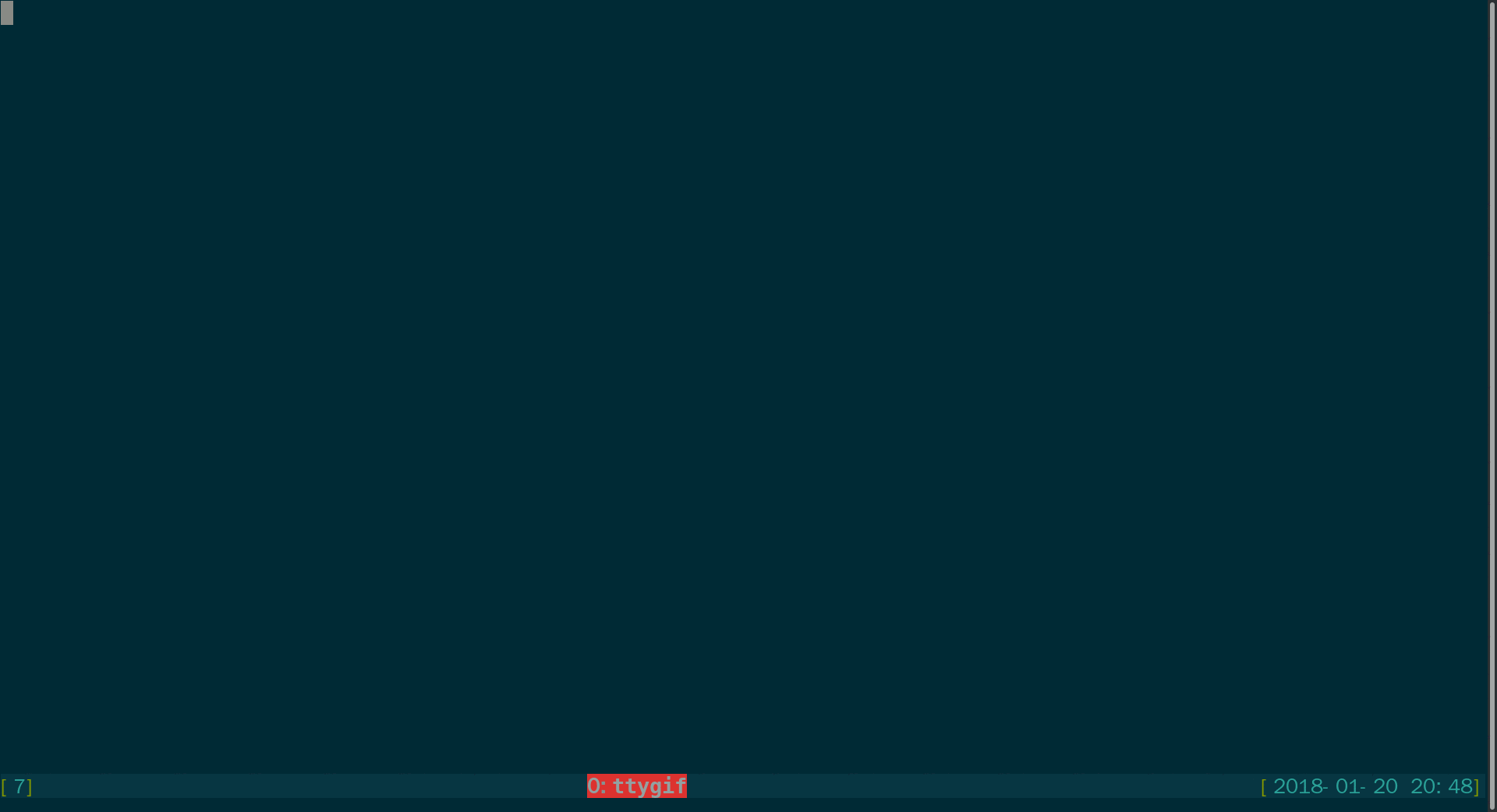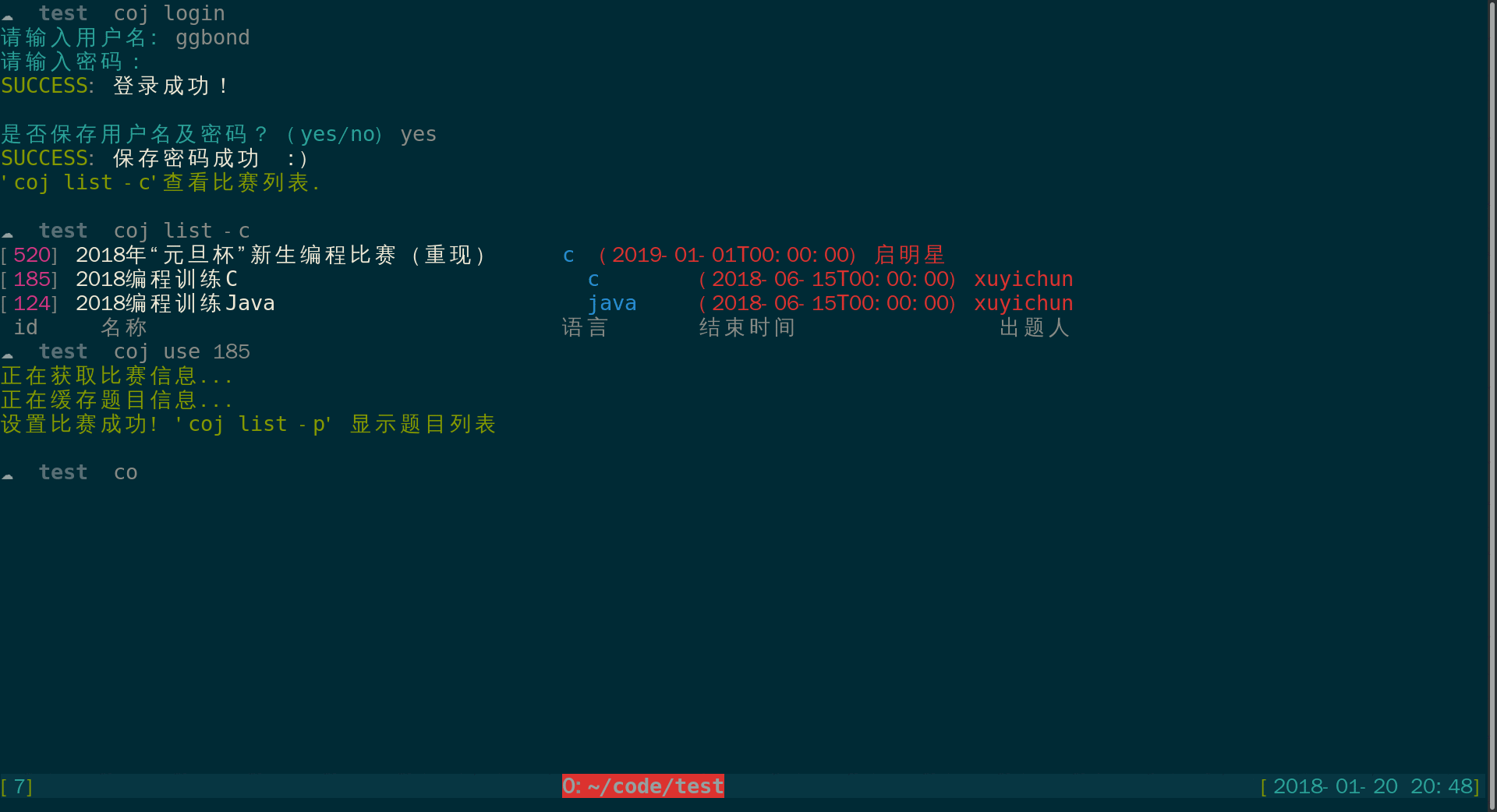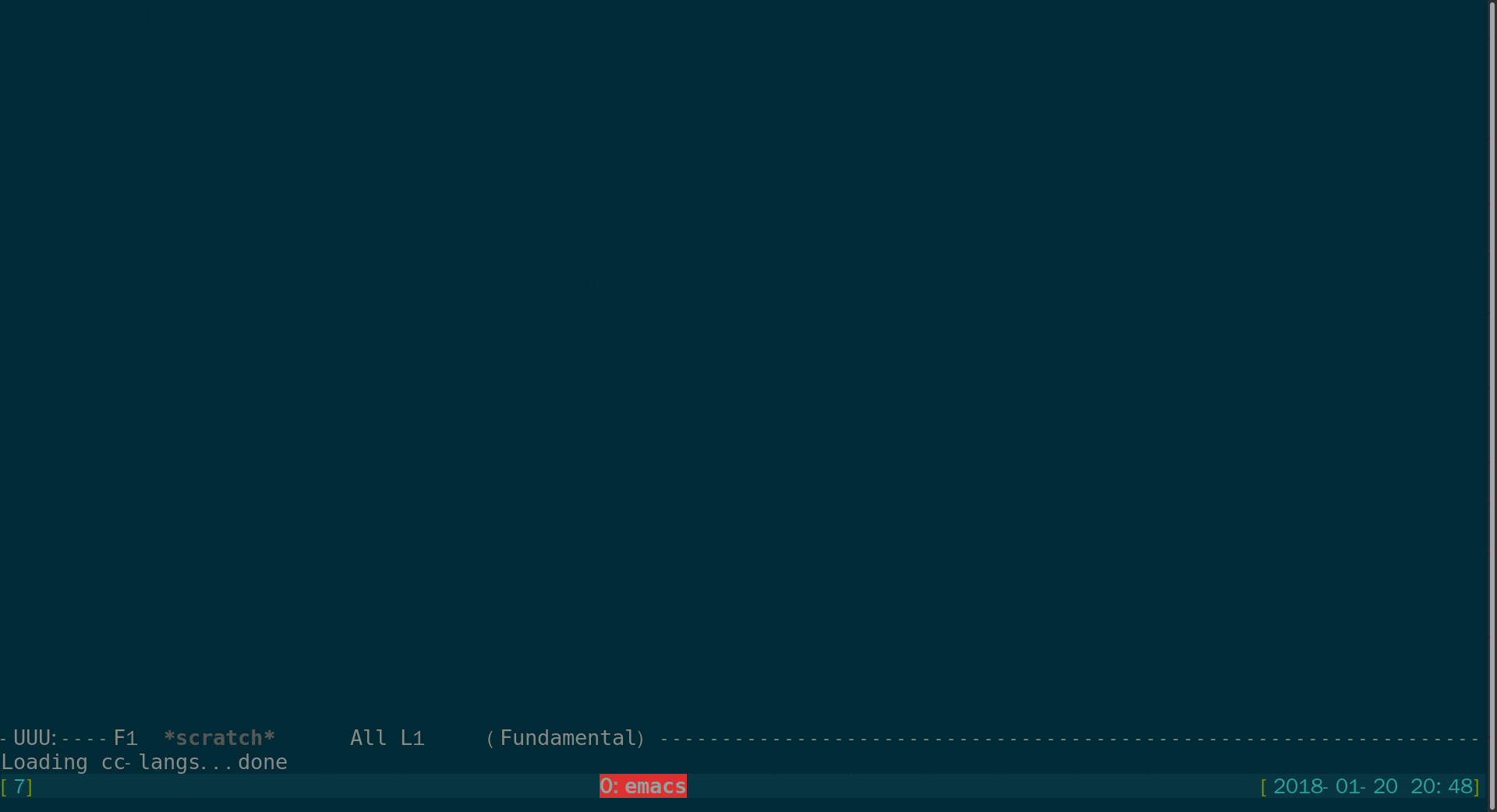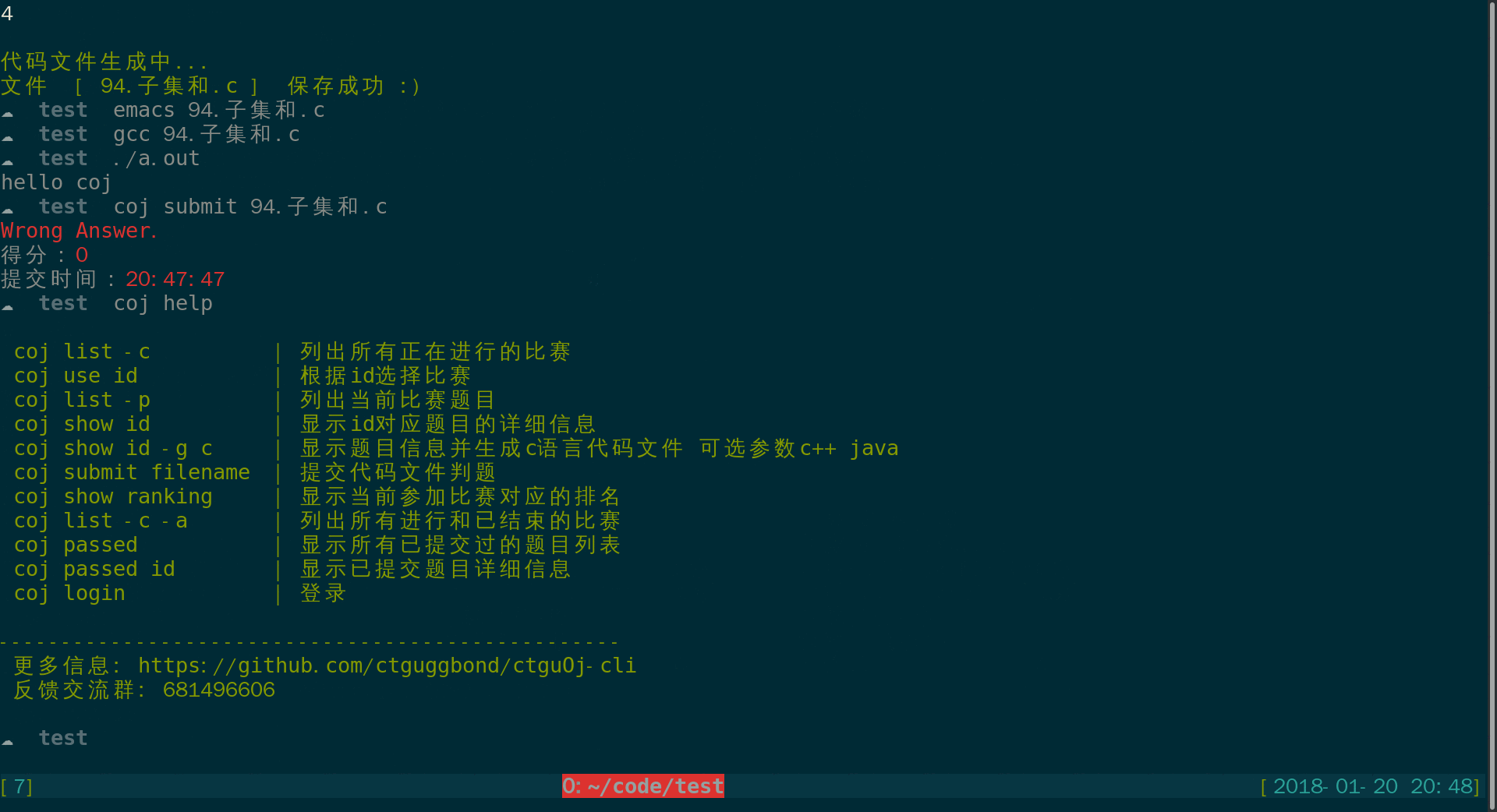
ctguoj list -c 显示比赛列表: 
ctguoj list -p 显示题目列表 
ctguoj show ranking 显示排名 
ctguoj submit id 提交题目 
ctguoj show help 显示帮助信息 
代码结构
leetcode-cli 用的js,所以只能模仿功能。 我在网上找了v2ex和网易云音乐命令行版python源码 学习借鉴.
api.py访问各个页面,返回页面对象response,验证码识别在内,网页请求用的requests.session() 得到session对象,保存cookie,加载cookie简化了很多操作:
session = requests.session() #得到session对象
data = {
'user.username': username,
'user.userpassword': password,
'verifycode':vcode
}
#发送登录请求,得到返回内容对象resp,data是登录参数
resp = session.post(login_url,data=data)
print(resp.text) #输出网页内容
#初始化cookie对象,.cookies是保存文件名
session.cookies = cookiejar.LWPCookieJar(".cookies")
#保存cookie,开始没加两个参数,保存cookie始终为空
#ignore_discard的意思是即使cookies将被丢弃也将它保存下来,
#ignore_expires的意思是如果在该文件中cookies已经存在,则覆盖原文件写入
session.cookies.save(ignore_discard=True, ignore_expires=True)
#加在cookie
session.cookies.load(ignore_discard=True, ignore_expires=True)
operator.py调用api内方法,得到页面html代码,用beatifulsoup解析显示,大部分代码在这里,比较重复,但是没个页面的结构不同,解析方法稍有区别,效率有待提高:
解析示例:
#初始化soup对象,resp.text为网页内容
soup = BeautifulSoup(resp.text,"lxml")
pList = [] #保存题目列表
#查找所有id为title_+数字 的div元素
allProblemDiv = soup.find_all('div',id=re.compile(r'title_\d*'))
#每个div块包含一个题目信息
for pdiv in allProblemDiv:
p = Problem() #自定义题目类
p.Pid = re.sub("\D", "",pdiv['id']) #获取题目id
p.title = pdiv.find('div',class_='nav').string.split('.')[1].strip() #题目标题
pList.append(p)
return pList
problem.py,contest.py,userInfo.py分别表示题目类,比赛类,用户信息类. 主要用于设置属性,格式化输出信息:以简化的userInfo为例:
class UserInfo:
#构造函数
def __init__(self):
pass
#打印用户信息
def showUserInfo(self):
#设置颜色
username = termcolor.colored(self.username, 'white')
#设置对齐占
username = '{:<{l}}'.format(username,l= 25-len(username.encode('GBK'))+len(username))
score = termcolor.colored(self.score, 'red')
#格式化输出
info = ''.join(rank + ' ' + username+' ' + name + ' ' + stuid+ ' '+ college + ' ' + major + ' ' + score)
print(info)
ctguoj.py接收命令行参数,根据参数调用operator.py 内相应方法.ShowMessage.py用于辅助输出提示,警告和错误信息.
不足与改进:
ctguoj.py中命令行参数解析可用 ArgumentParser,简化, 我全是if,else判断. 不过自己写的美观一些- BeatifulSoup 解析网页使用不够熟练,网页数据过多findAll查找解析较慢, 应该可以优化.
- 结构设计,对扩展不开放,对修改不关闭… 添加功能需改动代码较多,不易维护.
- 校oj网页结构还算简单,内网只能本校使用,开始应该搞一个nyoj,或者hdoj… 想了一下,万能模板好像也不太现实… 有想法的大佬可以一起做啊…